
- Tác giả

- Name
- Nguyễn Đức Xinh
- Ngày xuất bản
- Ngày xuất bản
Xây dựng Chatbot RAG thực tế với LangChain + FAISS + LLaMA
🧠 1. Tổng quan: Tại sao RAG là nền tảng của chatbot doanh nghiệp?
Trong khi LLM (như GPT, LLaMA, Mistral) có khả năng hiểu ngôn ngữ tự nhiên mạnh mẽ, chúng không thể “nhớ” kiến thức riêng của doanh nghiệp. Ví dụ, nếu bạn hỏi về chính sách nghỉ phép nội bộ hay hướng dẫn sử dụng hệ thống ERP, LLM sẽ không biết, vì những dữ liệu này không nằm trong tập huấn luyện.
👉 RAG (Retrieval-Augmented Generation) ra đời để giải quyết vấn đề này — cho phép LLM tra cứu dữ liệu thật trước khi trả lời. Hãy cùng xem quy trình đầy đủ.
⚙️ 2. Quy trình xử lý chi tiết của hệ thống RAG
Dưới đây là pipeline chuẩn khi triển khai một hệ thống RAG thực tế:
[1] Data Ingestion
↓
[2] Text Splitting (Chunking)
↓
[3] Embedding
↓
[4] Vector Storage (FAISS / Milvus)
↓
[5] Query Processing
↓
[6] Retrieval (Top-k)
↓
[7] Context Augmentation
↓
[8] Generation (LLM Response)
Hãy đi sâu từng bước 👇
🧩 2.1 Data Ingestion — Nạp dữ liệu nội bộ
Nguồn dữ liệu có thể là:
- PDF, DOCX, TXT, HTML
- Website nội bộ, API tài liệu
- Wiki công ty (Confluence, Notion, …)
Bạn có thể dùng LangChain hoặc Unstructured để trích xuất văn bản:
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("employee_handbook.pdf")
documents = loader.load()
✂️ 2.2 Text Splitting (Chunking)
LLM không thể xử lý văn bản quá dài (do giới hạn context window, ví dụ 8K–32K tokens). Vì vậy ta phải chia nhỏ văn bản thành các đoạn (chunk) có kích thước hợp lý.
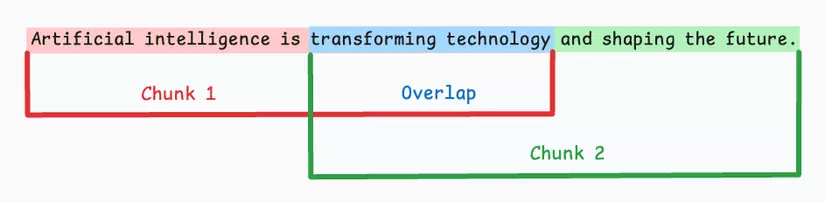
🔹 Best practice:
- Mỗi chunk: 300–800 tokens
- Dùng overlap 50–100 tokens để tránh “đứt câu”
- Giữ nguyên cấu trúc logic (đừng cắt giữa câu hoặc đoạn)
Ví dụ với LangChain:
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=100,
separators=["\n\n", "\n", ".", " "]
)
chunks = splitter.split_documents(documents)
📌 Lưu ý: Chunk tốt → retrieval chính xác hơn → câu trả lời mạch lạc hơn.
🔤 2.3 Embedding — Mã hóa văn bản thành vector
Mỗi chunk văn bản được chuyển thành vector (embedding) đại diện cho ngữ nghĩa. Sử dụng model embedding phổ biến:
sentence-transformers/all-MiniLM-L6-v2(nhẹ, miễn phí)intfloat/multilingual-e5-base(đa ngôn ngữ: Anh, Nhật, Việt, …)text-embedding-3-small(nếu dùng OpenAI API)
Ví dụ:
from langchain.embeddings import HuggingFaceEmbeddings
embedding_model = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-base")
vectors = embedding_model.embed_documents([chunk.page_content for chunk in chunks])
🧭 2.4 Vector Storage — Lưu trữ vector vào database
Dùng Vector Database để truy vấn nhanh bằng cosine similarity:
from langchain.vectorstores import FAISS
db = FAISS.from_documents(chunks, embedding_model)
db.save_local("vector_db")
Một số lựa chọn khác:
- FAISS (cục bộ, nhẹ, open source)
- Milvus / Weaviate / Pinecone (cloud, scale tốt)
💬 2.5 Query Processing — Xử lý câu hỏi người dùng
Người dùng gửi câu hỏi:
“Công ty có hỗ trợ làm việc từ xa không?”
Ta cũng tạo embedding cho câu hỏi này và truy vấn DB:
query = "Công ty có hỗ trợ làm việc từ xa không?"
docs = db.similarity_search(query, k=3)
k = số đoạn tài liệu liên quan cần lấy (thường 3–5).
🧩 2.6 Context Augmentation — Ghép tài liệu vào prompt
Ghép các đoạn tài liệu tìm được vào prompt trước khi gửi đến LLM:
context = "\n\n".join([d.page_content for d in docs])
prompt = f"""
Bạn là trợ lý AI nội bộ của công ty.
Dưới đây là tài liệu liên quan:
{context}
Hãy trả lời câu hỏi sau một cách chính xác và ngắn gọn:
{query}
"""
🧠 2.7 Generation — Gọi LLM sinh câu trả lời
Ví dụ với Ollama (chạy LLaMA hoặc Mistral local):
import requests
response = requests.post(
"http://localhost:11434/api/generate",
json={"model": "llama3", "prompt": prompt}
)
print(response.json()["response"])
Kết quả:
“Theo chính sách cập nhật tháng 3/2025, nhân viên có thể làm việc từ xa tối đa 3 ngày/tuần.”
✅ 3. Best Practice khi xây dựng hệ thống RAG
| Mục tiêu | Giải pháp |
|---|---|
| Tối ưu chunking | 300–800 tokens, overlap 10–15% |
| Cải thiện chất lượng retrieval | Dùng embedding tốt (E5, BGE, OpenAI Embedding) |
| Chống “đứt đoạn” | RecursiveCharacterTextSplitter hoặc Semantic Splitter |
| Tăng độ chính xác | Rerank kết quả bằng cross-encoder hoặc embedding model |
| Giữ context hội thoại | Sử dụng LangChain Memory hoặc ConversationBufferMemory |
| Giới hạn hallucination(ảo giác) | Thêm câu lệnh trong prompt: “Nếu không chắc, hãy trả lời ‘Tôi không biết.’” |
⚠️ 4. Các vấn đề thường gặp trong RAG
🧩 4.1 Context không khớp hoặc bị đứt đoạn
Nguyên nhân: Chunk quá nhỏ hoặc tách giữa câu. Cách khắc phục:
- Dùng
RecursiveCharacterTextSplitterhoặcSemantic Text Splitter - Giữ overlap ~10–15%
- Tránh tách ở giữa câu hoặc bảng biểu
🧠 4.2 Model trả lời sai dù tài liệu có chứa thông tin
Nguyên nhân:
- Kết quả retrieval không chính xác
- Prompt chưa rõ ràng Cách xử lý:
- Tăng
k(số đoạn lấy ra) - Sử dụng reranker như
bge-reranker-large - Thêm hệ thống “prompt template” hướng dẫn mô hình đọc tài liệu trước khi trả lời
🔄 4.3 Câu trả lời bị “hallucination”
Nguyên nhân: LLM suy đoán khi không có dữ liệu phù hợp. Cách xử lý:
- Trong prompt thêm:
"Nếu thông tin không có trong tài liệu, hãy trả lời: Tôi không chắc." - Giới hạn temperature thấp (0.1–0.3)
- Kiểm tra tài liệu nguồn trước khi hiển thị câu trả lời
🗂️ 4.4 Dữ liệu lớn, truy vấn chậm
Nguyên nhân: Vector DB chưa tối ưu hoặc embedding nhiều. Cách xử lý:
- Dùng approximate search (HNSW, IVF Flat) trong FAISS/Milvus
- Giảm dimension embedding (vd: 768 → 384)
- Cache kết quả truy vấn phổ biến
💬 4.5 Context hội thoại bị mất
Giải pháp:
- Dùng
ConversationBufferMemorytrong LangChain để lưu lịch sử hội thoại - Hoặc tạo custom memory store trong Redis
🧩 5. Kết hợp Fine-tuned model với RAG
Nếu bạn đã fine-tune một model LLaMA cho domain nội bộ (ví dụ: ngôn ngữ hành chính, từ vựng công ty), bạn có thể:
- Dùng model fine-tuned để hiểu câu hỏi chính xác hơn
- Dùng RAG layer để truy xuất dữ liệu mới nhất
➡️ Cấu trúc đề xuất:
[Query] → [Fine-tuned LLaMA (intent understanding)]
↓
[Retriever + FAISS + Documents]
↓
[LLM generation with augmented context]
↓
[Answer]
Kết hợp này giúp mô hình hiểu đúng ngữ cảnh + trả lời chính xác theo tài liệu nội bộ.
🚀 6. Kết luận
RAG không chỉ là “plugin tra cứu” cho LLM — nó là kiến trúc nền tảng để:
- Giúp AI trả lời dựa trên dữ liệu thật
- Giảm hallucination
- Và cập nhật kiến thức nhanh mà không cần fine-tune lại toàn bộ mô hình.
💡 Fine-tune giúp “dạy AI cách nói”, còn RAG giúp “dạy AI biết điều gì đúng”.